Select
AVPreserve Releases Interstitial – Free Error Detection Tool
3 September 2013
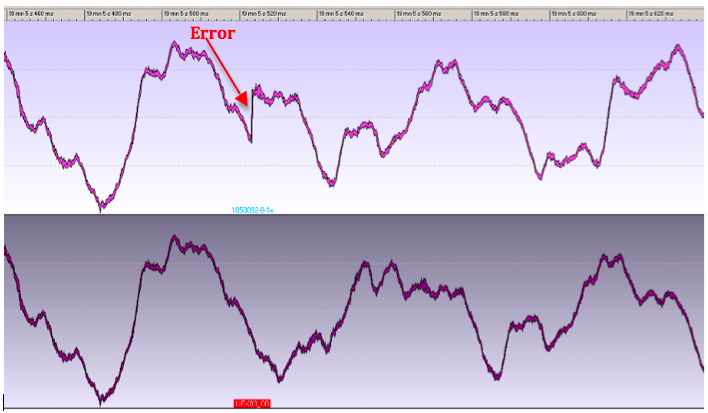
AVPreserve is pleased to announce the release of interstitial, a new tool designed to detect dropped samples in audio digitization processes. These dropped samples are caused by fleeting interruptions in the hardware/software pipeline on a digital audio workstation. The Interstitial tool Follows up on our work with the Federal Agencies Digitization Guidelines Initiative (FADGI) to define and study the issue of Audio Interstitial Errors.
interstitial compares two streams of digitized audio captured to a digital audio workstation and a secondary reference device. Irregularities that appear in the workstation stream and not in the other point to issues like Interstitial Errors that relate to samples lost when writing to disc. This utility will greatly decrease post-digitization quality control time and help further research on this problem.
interstitial is a free tool available for download via GitHub. Visit our Tools page for this and other free resources.
Toward Less Precious Cataloging
9 August 2013
For a number of years after college I was in the workers compensation and general liability industry, bouncing around among positions from file clerk to claims adjuster to data analyst. Somewhere in there I did transcriptions of phone interviews between adjusters and claimants. One of the more depressing parts of the job, I tried to distract myself by attempting to transcribe things as faithfully as possible, reflecting every single er, uhm, stutter, pause, and garbled sentence fragment. I wanted to reflect how people really spoke in all of its confusion and banal glory.
Also, coming out of literary studies, I forced myself to imagine there was some meaning to those various tics and patterns, but I also wanted to see how far I could stretch the plasticity of punctuation. What length of pause was a comma, a dash, a double (or triple!) dash, an elipsis? Are fragmented thoughts governed by semi-colons even if such marking was unintended by the speaker? One almost has to feel (or, at least I do) that under copyright law my expression of this recorded speech was so transformative that those transcriptions were wholly new works of art!
Did I mention I was very bored at this job?
It is true, however, that transcription is an art. It is the interpretation of information in one medium into another, not necessarily compatible, medium. I guess it wouldn’t be considered a fine art because it is more along the lines of didacticism — the direct communication of that information with maximal understanding as a goal, rather than an approach of impressionism, nuance, and open questions of interpretation.
But an art it is, requiring specialized knowledge to be done well and skill greater than just typing the words as they come. One can look at the frequent mistakes of spell check and speech-to-text, and consider the complex set of rules structured around such utilities, to appreciate how difficult written language is, in spite of our false sense of security in the rules of grammar. The ability of a text to be read by a machine does not confer infallibility and comprehension to that machine — on its own or as a conduit to a user. Despite Strunk & White’s efforts, there was a reason they wrote of elements of style.
*********************************
I find cataloging and related record creation to follow along these same lines. It too is a system of communicating information that is more of an art than its (multiple) rules based structures may suggest. It is also a system in which the art and stylistic traditions can and do fail machine readability, even when specifically designed for such.
You see, part of the art of cataloging is a series of visual tropes or signifiers that denote concepts or avenues of interpretation. For instance, [bracketed text]. This typically does not mean that there are actual brackets in whatever text, but rather may mean “This is an unofficial value I made the decision to assign to this field”…or maybe “I couldn’t read the handwriting and this is my guess”…or maybe “This is commentary, not actual information from the object”. Likewise brackets may be used to contain text such as […] or [?], which could mean “Unintelligible”, or “Maybe?”, or “Just guessin’ here”. (That last is my own way of sayin’ it.) One sees this frequently with titles, dates, and duration especially, though such visual signifiers may appear anywhere in a record.
And these markings are a thing of beauty — poetic layers of expression in six line strokes. A toehold of information in an uncertain world. A reflection of the cataloger’s fidelity to truth, even when it means admitting the truth is unknown and that one has failed in identifying it.
But.
But.
But, as at times can be the case, such art is impractical, limiting the efficiency of working with large data sets, or the advantage of machine readability to cleanup and search data, or the achievement of goals associated with minimal processing, which for archives is often the first pass at record creation.
As I have argued before, the outcomes of processing legacy audiovisual collections should support planning for reformatting and for collection management. This mean creating records at or near item level. This means data points like format, duration, creation date, physical characteristics, asset type, and content type must be quantified to some degrees. This means no uncertainties. There must be some kind of value for planning and analysis to work, whether it is an estimate or a guess or yeah-that’s-wrong-but-things-will-come-out-in-the-wash — or whether we just use common sense and context to support our assumptions rather than undermining them. This means be less precious.
The diacritics of uncertainty are meaningful, but when analyzing data sets they can push segments of records aside into other groupings when they likely shouldn’t be, and they make it difficult or impossible to properly tally data for planning and selection. A bracketed number or number with text in the same field is not a number to a machine. It cannot be summed. An irregular date cannot be easily parsed and grouped within a range. A name or term with a question mark is a different value than that same term with the question mark.
We know all of this — it is why we have controlled vocabularies and syntactical rules, and why we fret about selecting the “right” metadata schema. There is much theory around archival practice that comes down to exactness and authenticity of objects and documentation. However, there is a division in how such things are expressed and understood by a computer and by the human mind. There is also a division in exactness as data and exactness as a compulsive behavior. And any exactness is laid to waste by the reality of how collections are created.
When processing for reformatting, it must be kept in mind that the data created is not the record of record. It is a step to a complete record. It can be revised when content is watchable, or when embedded technical metadata gives us exact values like with duration. We know we are wrong or uncertain. The machine does not need to know it, cannot know it. But that fact will be apparent enough to future generations over time, as it is in so many other areas.
— Joshua Ranger
AVPreserve Second Lining It To SAA 2013
8 August 2013
AVPreserve Senior Consultant Joshua Ranger and Digital & Metadata Preservation Specialist Alex Duryee will be attending the Society of American Archivists 2013 Annual Meeting in New Orleans next week.
Josh will be presenting on the panel “Streamlining Processing of Audiovisual Collections” (Session 309) on Friday morning along with expert colleagues from the Library of Congress and UCLA. He will be discussing approaches AVPreserve uses in processing collections and performing assessments as outlined in his white paper “What’s Your Product”, as well as the AVCC and Catalyst tools we have developed to support efficient inventory creation.
Alex will be presenting in Tuesday’s Research Forum “Foundations and Innovations” on the topic of compiling and providing access to large sets of email correspondence.
We’re excited to be contributing as members of SAA this year and look forward to seeing friends old and new. We love to chat about media archiving, so look for us and stop and talk — it will be too hot to do anything else in NOLA. And oh yeah, buttons
New Tools In Development At AVPreserve
10 July 2013
AVPreserve is in the finishing phases of development for a number of new digital preservation tools that we’re excited to release in the near future.
Fixity: Fixity is a utility for the documentation and regular review of checksums of stored files. Fixity scans a folder or directory, creating a database of the files, locations, and checksums contained within. The review utility then runs through the directory and compares results against the stored database in order to assess any changes. Rather than reporting a simple pass/fail of a directory or checksum change, Fixity emails a report to the user documenting flagged items along with the reason for a flag, such as that a file has been moved to a new location in the directory, has been edited, or has failed a checksum comparison for other reasons. Supplementing tools like BagIt that review files at points of exchange, when run regularly Fixity becomes a powerful tool for monitoring digital files in repositories, servers, and other long-term storage locations.
Interstitial Error Utility: Following up on our definition and further study of the issue of Audio Interstitial Errors (report recently published on the FADGI website), AVPreserve has been working on a tool to automatically find dropped sample errors in digitized audio files. Prior to this, an engineer would have to use reporting tools such as those in WaveLab that flag irregular seeming points in the audio signal and then manually review each one to determine if the report was true or false. These reports can produce 100s of flags, the majority of which are not true errors, greatly increasing the QC time. The Interstitial Error Utility compares two streams of the digitized audio captured on separate devices. Irregularities that appear in one stream and not in the other point to issues like Interstitial Errors that relate to samples lost when writing to disc. This utility will greatly decrease quality control time and help us further our research on this problem.
AVCC: Thanks to the beta testing of our friends at the University of Georgia our AVCC cataloging tool should be ready for an initial public release in the coming months. AVCC provides a simple template for documenting audio, video, and film collections, breaking the approach down into a granular record set with recommendations for minimal capture and more complex capture. The record set focuses on technical aspects of the audiovisual object with the understanding that materials in collections are often inaccessible and have limited descriptive annotations. The data entered then feeds into automated reports that support planning for preservation prioritization, storage, and reformatting. The initial release of AVCC is based in Google Docs integrated with Excel, but we are in discussions to develop the tool into a much more robust web-based utility that will, likewise, be free and open to the public.
Watch our Twitter and Facebook feeds for more developments as we get ready to release these tools!
AMIA 2013 Presentations
8 June 2013
AVP was involved in a number of panels and events at the 2013 Association of Moving Image Archivists Conference in Richmond, Virginia, including organizing the first ever AMIA HackDay and presentations related to the imminent decay of magnetic media, the importance of metadata development for digital preservation, and the intricacies of vendor selection for digital asset management systems.
- CHRIS LACINAK “THE END OF ANALOG MEDIA: THE COST OF INACTION AND WHAT YOU CAN DO ABOUT IT” (PDF)
- MIKE CASEY, INDIANA UNIVERSITY, “WHY MEDIA PRESERVATION CAN’T WAIT THE WEATHERING STORM” (PDF)
- AMIA & DLF HACKDAY 2013 PROJECTS (Wiki)
- SETH ANDERSON, “NAVIGATING THE DIGITAL ARCHIVE: FIRST, KNOW THYSELF” (PDF)
- SETH ANDERSON, “MASTERING YOUR DATA: TOOLS FOR METADATA MANAGEMENT IN AV ARCHIVES” (PDF)
- KARA VAN MALSSEN “FROM ZERO TO DAM” (PDF)
MARAC 2013 Presentations
8 June 2013
The Mid-Atlantic Region Archives Conference epitomizes the importance and reach of regional professional organizations, opening educational and networking opportunities to broader audiences that cannot regularly attend national conventions. AVP was a proud first-time participant on two panels this year on the topics of preserving complex digital artworks and the refinement of archival data using tools such as Open Refine. We look forward to presenting at future meetings.
AVPreserve At NYAC 2013
30 May 2013
AVPreserve President Chris Lacinak will be chairing a panel at the upcoming New York Archives Conference to be held June 5th-7th in Brookville, New York. NYAC provides an opportunity for archivists, records managers, and other collection caretakers from across the state to further their education, see what their colleagues are doing, and make the personal connections that are becoming ever more important to collaborate and look for opportunities to combine efforts. We’re pleased to see that this year’s meeting is co-sponsored by the Archivists Round Table of Metropolitan New York, another in their critical efforts to support archivists and collections in New York City and beyond.
Chris will be the chair for the Archiving Complex Digital Artworks panel with the presenters Ben Fino-Radin (Museum of Modern Art), Danielle Mericle (Cornell University), and Jonathan Minard (Deepspeed Media and Eyebeam Art and Technology Center). It’s hard to believe, but artists have been creating digital and web-based artworks for well over 20 years, and the constant flux in the technologies used to make and display those works has brought a critical need for new methodologies to preserve the art and the ability to access it. Ben, Danielle, and Jonathan are leading thinkers and practitioners in the field and will be discussing the fascinating projects they are involved with. We’re proud to work with them and happy their efforts are getting this exposure. We hope to see a lot of our friends and colleagues from the area in Brookville!
New Software Development Services At AVPreserve
29 May 2013
One of the core concepts behind the work we do is that because the necessary tools for media collection management and preservation have been limited in scope and because the need for such tools is so urgent, it is up to us as a community to develop those tools and support others who do as well, rather than hoping the commercial sector will get around to it any time soon in the manner we require. This has been an important factor of why AVPreserve has looked to open source environments in developing utilities such as DV Analyzer, BWF MetaEdit, AVI MetaEdit, and more.
While most are aware AVPreserve has been a part of developing those desktop utilities, over the past year we have been doing a greater amount of work in the design and development of more complex, web-based systems we are using for the various needs of cataloging, managing and updating metadata, collection analysis, and digital preservation. With the collaboration of our regular development team and the designer Perry Garvin we work on all aspects of frontend and backend development, from needs assessment to wire-frames, implementation, and support. Some of the projects we have been working on are entirely built up from scratch, while others focus on implementation of existing systems or the development of micro-services that integrate with those systems to fill out their abilities for managing collections.
Some of our new systems include:
Catalyst Inventory Software:
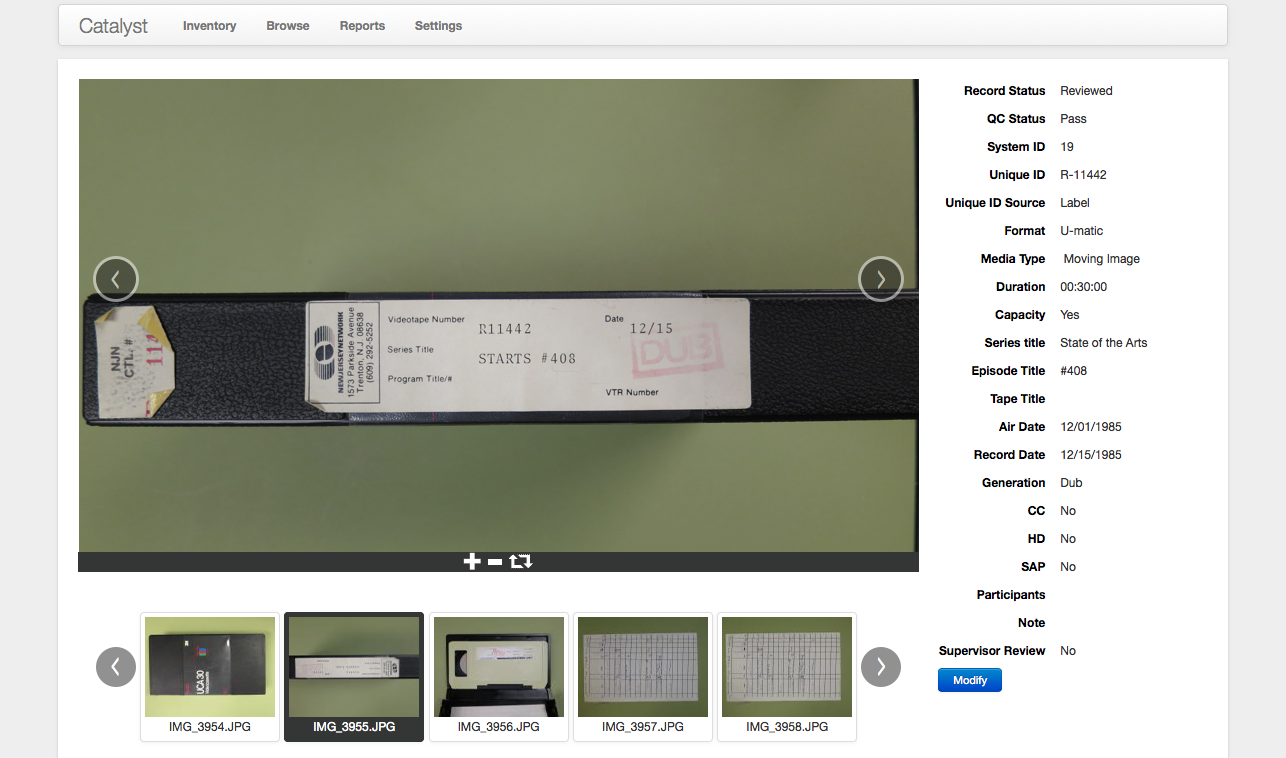
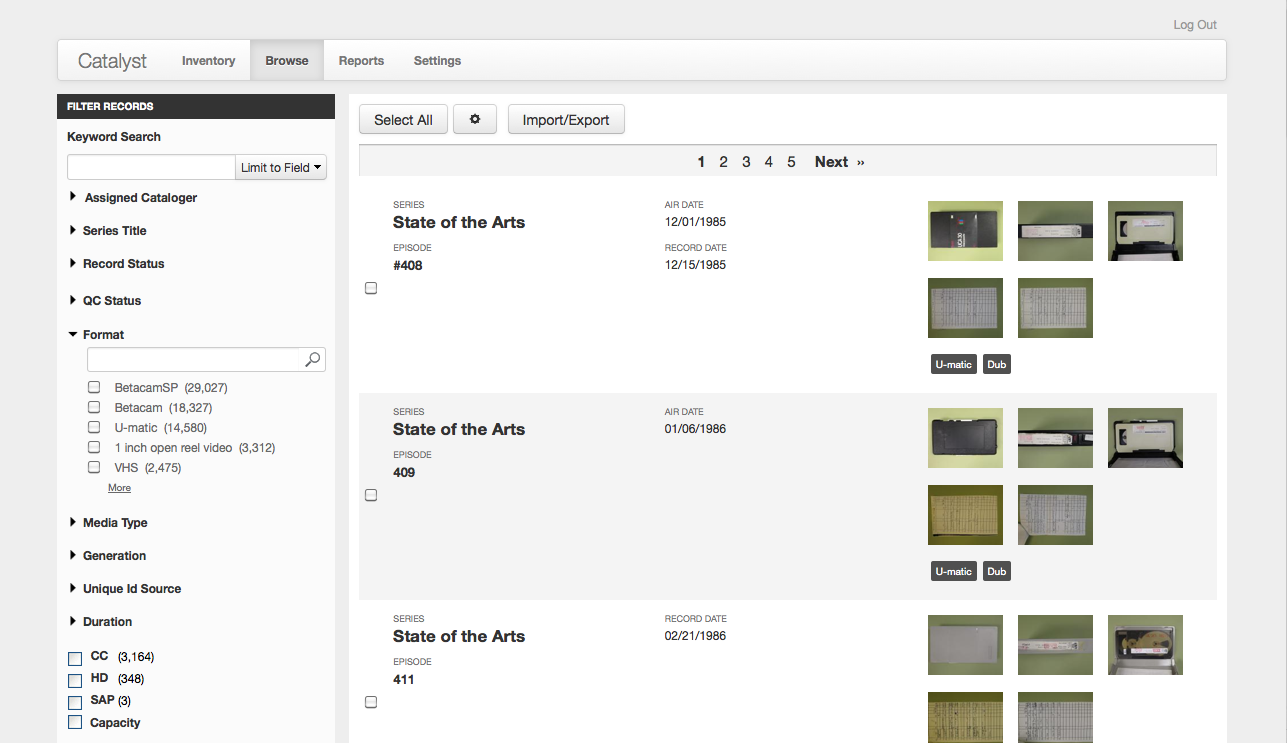
In support of our Catalyst Assessment and Inventory Services we developed this software to support greater efficiency in the creation of item-level inventories for audiovisual collections. At the core is a system for capturing images of media assets, uploading them to our Catalyst servers, and them completing the inventory record based on those images. Besides setting up a process that limits disruption onsite and moves the majority of work offsite, Catalyst also provides an experience-based minimal set of data points that are reasonably discernable from media objects without playback. This, along with the use of controlled vocabularies and some automated field completion, increases the speed of data entry and provides an organization with a useable inventory much quicker. Additionally, the images provide information that is not necessarily transcribable, that extends into deeper description beyond the scope of an inventory, or that may be meaningful for identification beyond typical means. This may include run down sheets or other paper inserts, symbols and abbreviations, or extrapolation based on format type or arrangement. Search and correct identification can be performed without pulling multiple boxes or multiple tapes, and extra information can be gleaned from the images. Catalyst was recently used to perform an item-level inventory of a collection of over 82,000 items in approximately three months.
AMS Metadata Management Tool
The AMS was built to store and manage a set of 2.5 million records consolidated from over 120 organizations. The system allows administrative level review and analytic reporting on all record sets combined, as well as locally controlled and password protected search, browse, and edit features for the data. This editing feature integrates aspects of Open Refine and Mint to perform complex data analysis quickly and easily in order to complete normalization and cleanup of records or identify gaps. Records are structured to provide description of the content on the same page along with a listing of all instantiations of that content where multiple copies exist, while also providing streaming access to proxies.
Indiana University MediaScore
AVPreserve’s development team supported Indiana University in the design and creation and MediaScore, a new survey tool used to gather inventories of collections. Within MediaScore assets are grouped at the collection or sub-collection level and then broken down by format-type with like characteristics (i.e., acetate-backed 1/4″ audio, polyester-backed 1/4″ audio, etc.), documenting such things as creation date, duration, recording standards, chemical characteristics, and damage or decay. This data is then fed into an algorithm that assigns a prioritization score to the collection based on format and condition risk factors. In this way the University is able gather the hard numbers they need for planning budgets, timelines, and storage needs for digitization their campus-wide collections while also providing a logic for where to start and how to proceed with reformatting a total collection of over 500,000 items that they feel must be addressed within the next 15 years.
**************
These are just a few of the projects we’re working on right now. We’re thrilled to be augmenting our services this way and to be able to provide fuller support to our clients, as well as to continue developing resources that will contribute to the archival field. We’re looking forward to new opportunities collaborate and provide solutions in this way.
AVPreserve Welcomes Alex Duryee
24 May 2013
AVPreserve is pleased to welcome Alex Duryee to our team. Alex is a 2012 MLIS graduate from Rutgers University with a specialization in Digital Libraries and comes to us from Rhizome where he worked on the preservation of net- and disc-based artworks. Experienced in web archiving, data preservation, and the migration of content from optical and magnetic digital storage, Alex is working on a number of digital preservation projects with us. These range from developing new tools and software for support of integrity assurance for digital repositories and audio transfers (extending on our work with BWF MetaEdit and Digital Audio Interstitial Errors, to analysis and normalization of a dataset consisting of 2.5 million records. The work he is doing is a part of our growing focus on developing tools and support for managing metadata and digital files in a preservation environment. We’re excited to add this to our continuing services involving physical collections and excited to have Alex on board!
Does The Creation Of EAD Finding Aids Inhibit Archival Activities?
22 May 2013
One of the primary outcomes of processing is establishing access to collections, traditionally assumed to be enabled by arrangement and description of materials and generation of a finding aid. The theory here is if you can find an item’s exact (Or approximate. Or possible.) location within a shelf or box or folder, you can access it.
If I haven’t explicitly stated it, I hope that some of my other posts have at least inferred that this concept is a fallacy, because the discovery of an audiovisual item does not assure accessibility to its content if that object is not in a playable condition. Access may come eventually through a reformatting effort or researcher request, but that is not a certainty.
This is why I have written that, in most cases, the outcomes of processing audiovisual material needs to focus on planning and preservation activities first. The archivist’s responsibilities include provision of findability, accessibility, and sustainability to collections. Processing has the capability of hitting at least parts of all of these marks, but, given that a focus of processing is generation of a finding aid, those responsibilities can at times be seen through that prism, the every problem looks like a nail thing. The danger here is the potential for the finding aid to become the endpoint rather than a stepping stone to further collection management, especially in institutions dealing with severe backlogs and growing collections.
Of course it can’t be expected that all archival activities support all needed outcomes. However, in spite of the traditional thinking that multiple touches of the object for cataloging or processing lead to an increase in the cost of managing that asset, I feel we have to start looking at the approach of making multiple passes on the object and its content in order to help achieve description, accessibility, and persistence.
If we are looking to optimize the use of resources by focusing on the outcomes they support, we need to ask if those outcomes are being optimally realized. In other words, if we are focused on producing finding aids, are those actually doing the job we think they are.
To put it succinctly, no, not in the way they could and the way they need to be.
I’m talking specifically here about EAD-based finding aids. I will not discuss the structure of that schema here nor the structure of DACS because, though they have not been ideally suited for audiovisual collections in the past, that is not the issue here. Rather, the issue is that EAD finding aids are not doing the job of being findable because EAD is not discoverable through Internet search engines, and the records or online aids themselves are frequently segregated from the library’s catalog or main site.
Even in cases where box and folder browsing is sufficient for onsite access, this lack of integration and external searchability inhibit discovery and use by a wider community. And we’re not really talking anything complex here like linked open data or developing a brand new schema. EAD already has an LOC (and likely other) approved crosswalk to MARC and other standards. With legal exceptions, why wouldn’t all finding aid records also be in the main library catalog? And why are finding aids frequently buried within the Library website under multiple clicks to the Special Collections and Archives (which may even be divided out further if an organization has multiple archive divisions) rather than being front and center along with access to the public catalog?
I understand that there are often extenuating circumstances here, such as collections with access restrictions or sensitive content. However I can’t help but suspect that this segregation is in part self-imposed, coming out of an outdated paranoia about limiting access to “approved” researchers or obscuring the contents of a collection to avoid legal issues. Or, alternatively, self-imposed by the enforcement of traditions and standards that have, for the large part, failed to adapt to changes in culture and technology. Changes which, to be honest, are not new. Motion pictures have been around for over 100 years. We’ll see how well the new DACS addresses audiovisual content, but, even if the issue is slightly better resolved, why has it taken this long?
There is nothing inherently wrong with the concept of finding aids, but there is something wrong with funneling resources into an inefficient system. This was the lesson of MPLP, though Meissner and Greene’s approach was to attack the inefficiency of the methodology. Having reviewed that, we also need to review the outcome of that method similarly and ask if the outcomes are meeting the needs of those we serve — our users, our institutions, and our collections — and if the outcomes support sufficient return on the investment of resources.
We have to admit that we often have a limited opportunity to test that ROI because, in part, the lack of access perpetuated by inadequate means of findability creates a self fulfilling prophecy of lack within archives. At administrative levels, limited resources are allocated to collections because limited access suggests such resources are not necessary. At the ground level, that lack of resources makes caretakers wary of promoting greater access because providing that access is difficult to support by under-staffed departments, and so they do not (or cannot, as is often the case with audiovisual materials). Back at the administrative levels, usage or request reports show that rates are not significantly increasing, proving that resource needs remain minimal because requests and fulfillment of access to records is minimal. And the cycle continues. No one is served. Not the administrator, nor the archival staff, nor those whom they aim to serve.
Frankly speaking, the search portals in libraries and online are probably better and certainly more user friendly than EAD finding aids. I’m not saying we need to jettison finding aids entirely because they contain much information that supports context, provenance, collection management, and other archive-specific or internal data. Rather, what we need to focus on more is how we can shape the creation of finding aids so that the data can be mapped to other portals users are more likely to access in a manner that is simple to achieve, does not lose meaning in the migration, and supports the needs expressed in those other systems. Likely this means that EAD is just one of many forms the data takes, not the ultimate container.
There are of course archival institutions working beyond EAD in innovative areas, but overall we have to accept that findability and access are no longer centralized, and realize that the structure of EAD finding aids and the manners in which they are distributed ignore or actively work against that fact. Only by integrating with other systems and technologies can archives maintain necessary authority over their records, more fully supporting archival services and responsibilities in a changing landscape.
— Joshua Ranger