What is the chemistry of digital preservation?
February 18, 2016
When we develop preservation strategies for paper-based materials an essential consideration is the underlying chemistry of the physical materials themselves. Paper is an organic compound, made of cellulose fibers, or, sometimes, a mix of cellulose and lignin fibers. Cellulose is a polysaccharide of carbon, hydrogen, and oxygen atoms, C6H10O5.
Cellulose is hydrophilic (attracted to water) and not hydrophobic (repelled from water). Additionally, we know that cellulose is hydrolytic; not only is cellulose attracted to water, but when it comes into contact with water, the molecular bonds will begin to breakdown. This is called hydrolysis, and it occurs with direct contact with water as well as with exposure to moisture (humidity) in the air. Because of this understanding of the behavior of the molecules that constitute paper materials, we can design preventive preservation techniques to prolong the life of stored paper materials and to minimize undesired changes to them overtime. We can store them in protective boxes in dry locations away from water sources. Of course, there are other characteristics of cellulosic materials that we use to infer preservation strategies for paper, e.g., low light exposure, low acidity exposure, etc. But my point is that when we understand the construction of materials, as archivists, we are better suited to design preservation strategies that will work. We need to bring the same level of understanding to digital file-based materials that we have traditionally brought to physical materials such as paper.
Last summer I began a project to design a training curriculum focused on examining the digital file-based equivalent of paper and other physical materials, the file format. Because I believe that if we, as archivists, are going to be able to take care of digital collections into the future, we need to understand the basic building blocks just as we have labored to understand the chemistry of physical collections. So, I asked myself, what is the counterpart in the digital world? Certainly we must understand the physicality of hard drives, digital tape, SSD technology, optical media, and other storage devices for digital information. But if we think of these things as the equivalent of our shelves and boxes and folders, what is the digital equivalent of paper, and photographs, and other 2-D materials stored in archives? Well, that would be files, and other data sources, too, of course. And, what is the equivalent of knowing that paper is cellulosic? I guess that would be the knowledge that files are constructed of bits, and bytes, and guided by format specifications, and stored in file systems. From this logic, I began to construct a discourse around the concept of “the chemistry of digital preservation.” To know files, we must know how they are constructed. We must be able to dissect them. We must understand how they decompose, and how they are kept alive, and how to correct them if they are broken. And from this knowledge, we will be better equipped to design preservation strategies for our digital collections. With these things in mind, let’s explore the building blocks of a digital file.
BITS
It all starts with a bit. What is a bit? Literally it is a binary digit: a 1 or a 0. Binary itself is not an electronic thing. Binary is a counting system, a positional notation system, similar to our more commonly known decimal counting system, but instead of ten characters used to represent values, binary only has two characters: 0,1. This means that we open up new positions much faster when we count and each new position is multiplied by a factor of two.
For example:
Binary Decimal
0 0
1 1
10 2
11 3
100 4
101 5
110 6
111 7
1000 8
To count to ten in binary, we do this:
1010
Which is really (in decimal), “8” + “0” + “2” + “0” = “10”.
In computing, bits are used to store values. Sometimes the value stored is actually a single value, sometimes bits are grouped into sets of 8 (bytes) or 16 (words) or 32 (double words), etc. to store larger values.
BYTES
A byte is a grouping of eight bits that is often used to store information in computing. Because a byte is an 8-bit value, it can contain any value from 0 to 255. Eight binary digits together can express a total of 256 values. When we put multiple bytes together, we can express even more information. A word is typically two bytes, or a 16-bit value. Sixteen binary digits together can express any value from 0 to 65,535, or a total of 65,536 possible values. There are further complications to understand, e.g., whether this is an integer or a float, signed or unsigned, little endian or big endian. This being a blog post, I’m not going to go into every detail here. The message, however, is that bits, bytes, and combinations of bytes form the basic building blocks of digital files.
FILES
A file, really, is only a string of bytes. From the first byte to the last byte. And it must be addressable (read: indexed and findable) by a file system so that it is clear where the string of bytes is stored on the physical storage device. The most basic file is a simple text file made up of ASCII characters. This file has no true format short of the knowledge that the bytes in the file represent ASCII characters.
This string of characters highlighted in the red box in the following image is a hexadecimal representation of the bytes that make up a single file:
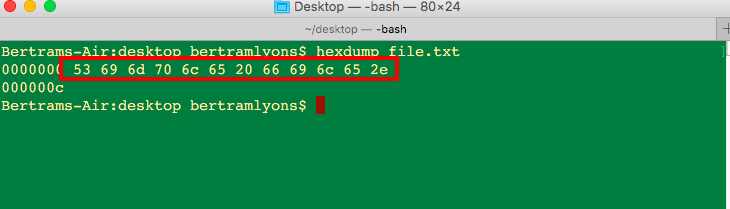 file.txt | hexadecimal view of the 12 bytes of the file
file.txt | hexadecimal view of the 12 bytes of the file Hexadecimal is another positional counting system, similar to decimal and binary. It has 16 unique characters that can be used to count: 0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f. So each new position is a factor of 16, instead of 10 (decimal) or 2 (binary). Hexadecimal is a shorthand way to represent bytes (8 bits) because (as I mentioned above) a byte can represent 256 values and (as luck would have it) a two-character hexadecimal value can represent up to 256 values, too. So, we can save space and represent bytes as two-digit hexadecimal values: from 00 to ff. The string of values in the red box above represents the 12 bytes of my file: file.txt. These are all the bytes in the file. In this case they are read from left to right.
If I open this file on my computer, I see the file is this:
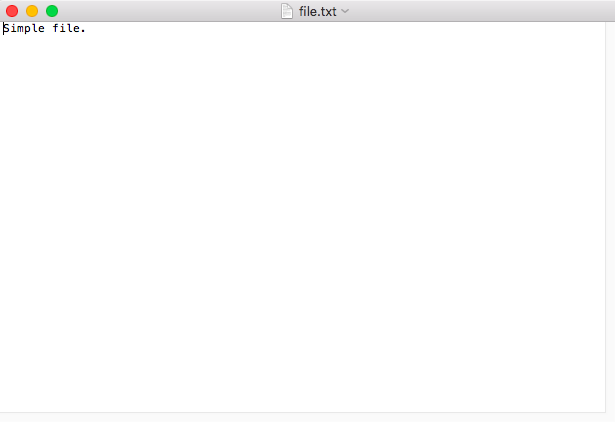 file.txt | Simple file.
file.txt | Simple file. It reads, “Simple file.” And it is a .txt file. If you were to use the ASCII chart to translate the hexadecimal byte values listed above, you’d see that they translate exactly to “Simple file.” So that’s a file. (But, of course, they only get more complicated from here.)
FORMATS
Now that we have covered the basic building blocks of files, we can delve a bit into the complexities of formats. In order to encode more complex information, and to use files in the context of certain software, we have the concept of formats. A format is really a recipe for constructing a specific type of file. The format specification defines how bytes are interpreted throughout the file, how they are grouped, what they represent at various locations in the file, and how the values are interpreted to communicate the intended encoded information. The formats, in essence, are the compounds of digital preservation. There are rules for their construction, and certain molecules (bytes) and atoms (bits) are used in unique ways depending on the format specification.
In the previous file example, there was nothing to the file but the content of the file itself. Let’s think about a photograph for a moment. For a digital image, the content would be the image itself. The captured color and brightness information that can be translated to a recognizable image for a human to see and understand. We can use software to view this image and evaluate the color and brightness characteristics of the pixels. We can use context to understand what we see in that image and what we can learn from examining it with our eyes. This is all the information contained within the file that represents the encoded information that the file was intended to transmit.
These types of complex formats require more structural information within the bytes (and support more embedded information) to allow a software program to properly decode the image data so that it is understandable to a human in the way it was intended. For the digital image example, this information may include color space, height, width, bits per sample, or date created. The particular file format specification stipulates how and where this information is encoded (or declared) within the file and how the bytes are used to store this information.
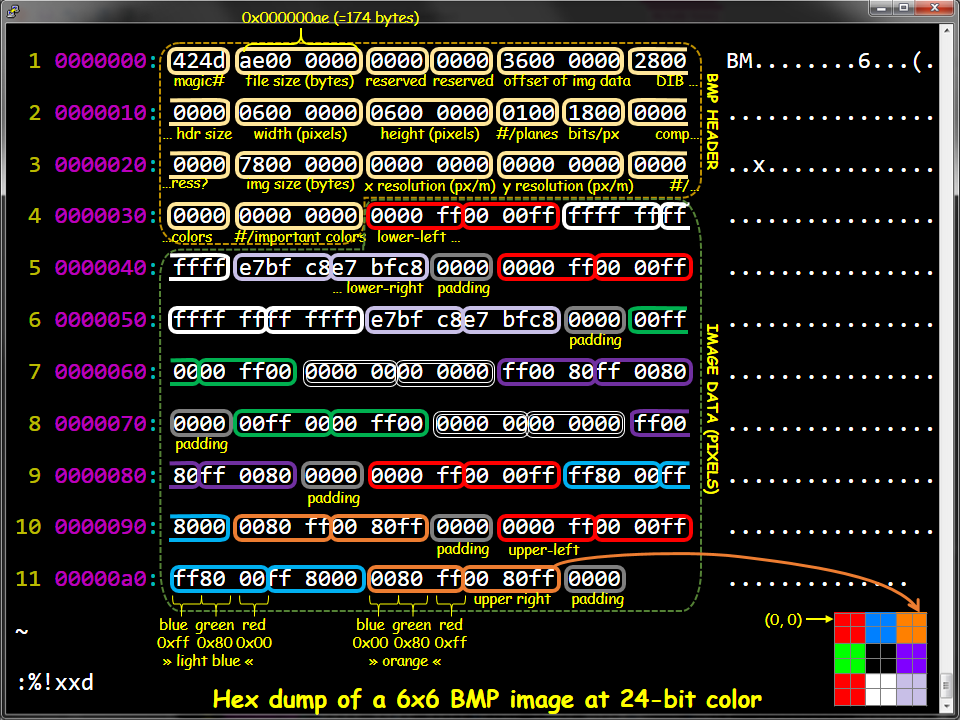 Excerpt of BMP file seen through hexadecimal representation of the bytes of the file. There are annotations to help you understand how certain bytes represent certain information (all based on the BMP format specification — the recipe.). Borrowed from URL: https://engineering.purdue.edu/ece264/15au/hwimages.
Excerpt of BMP file seen through hexadecimal representation of the bytes of the file. There are annotations to help you understand how certain bytes represent certain information (all based on the BMP format specification — the recipe.). Borrowed from URL: https://engineering.purdue.edu/ece264/15au/hwimages. FILE SYSTEMS
In order to write files to a storage medium we need a way to access and manage those files. This is done using file systems. Think here of Windows NTFS or Mac HFS+ or the ISO 9660 Optical Media file system. I mentioned earlier that a file must be addressable. In order to keep track of where files are stored on digital storage media, file systems are used to index files, track permissions, document dates of modification and creation, remember storage locations, and support findability of files by users and computers. While the more commonly known file systems are mentioned above, there are many varieties of file systems depending on the operating systems and storage devices in use. At any given time, a file is known by a file system and this system stores information about the file that the file itself is unaware of, e.g., filename. Most files do not know their names. The file system forms the context in which a file’s provenance is known.
IN PRACTICE
So how does this all come into focus in the context of archives? Here’s an example. A common concern for archivists responsible for the care of digital files is the preservation of create, modify, and access dates (sometimes known as m/a/c dates, also known as stat metadata) for the files in their custody. There are a lot of moving parts related to the preservation of this information (and the solutions are different in different situations), so I’ll provide a single example here to demonstrate some of the issues (all of this ties back to understanding the chemistry of digital preservation).
My colleague and friend, Doug Boyd at the University of Kentucky, may decide to collect a born-digital oral history recording created by a researcher in Bowling Green, KY. The researcher has created this file as a WAV file and it is stored on his personal Mac laptop currently. Doug has decided that he is interested in collecting the recorded audio (the content in the file) as well as documenting the time the file was created on his donor’s computer as well as the date and time the file was last modified by the researcher before transferring custody of the file to Doug. Knowing that this is a WAV file, Doug can take a look at the RIFF/WAV format specification to understand the types of information that he can expect to be stored within the bytes of a typical WAV file. Doug will see very quickly that create and modify dates are not stored within the actual bytes of standard WAV files. (Doug knows that the Broadcast Wave – BWF – extension by the European Broadcast Union do support embedding of create dates, but he already verified with the donor, that the donor did not create the file with the BWF metadata extensions.) At this point, Doug has used his understanding of formats, files, and bytes to verify whether or not the information he desires exists within the file. He can evaluate the bytes in the file himself or use a tool such as MediaInfo or ffprobe to confirm his understanding and verify that there are no embedded dates within the file. Knowing this, he can be sure that preserving the integrity of the file (using a checksum, for example) will preserve the recorded sound, but will not ensure that he retains m/a/c dates for the file moving forward.
So where are these dates, then? Doug is sure that the donor’s computer knows this information about the WAV file. Doug has seen this information when he looked at the properties of the file using the Mac’s finder window. These m/a/c dates, it turns out, reside in the file system used by the Mac to manage the storage of content on the attached hard drive. This information is not stored in the file; it is stored in the file system. Doug will have to take additional measures to ensure that he captures these dates. Here, Doug has many options. He could use the Mac’s “ls” command to write the dates to a text file and then save that text file as a sidecar file that travels with the WAV file. He could create a disk image that copies the file system and the files on the donor’s hard drive (although for one WAV file, he may not take this approach). He could use a TAR or ZIP serialization technique and attempt to have those programs capture these dates in the serialization package (this is possible, but not always successful). How he captures this data is up to Doug, but because he understood the building blocks of digital information he was able to develop a preservation strategy for this acquisition that met his requirements. He understood the bits, bytes, files, formats, and file systems at play and he was able to see how all of these parts come together to form the content information that he was trying to preserve.
CHEMISTRY OF DIGITAL PRESERVATION
I’m scratching the surface here, but I think there are opportunities to continue this line of thinking for digital preservation specialists. There is an opportunity for a new curriculum of study that establishes a foundation for digital preservation supplemental to the traditional organizational approach to understanding digital preservation. Archivists have much to learn from computer scientists in this domain. If we know our collections at the elementary levels, we can be better equipped to care for these collections, to design preventive preservation techniques, to perform conservation treatments when necessary, and to ensure the long-term accessibility of our records in the face of continued technological obsolescence and change.